Pangeo¶
In December 2016, a small group of scientists and software engineers, including Ryan Abernathey, Joseph Hamman, Matthew Rocklin, and many others (even I was there!), met at Columbia University for the Columbia AOSPY Workshop to discuss the future of a Python “toolkit for the analysis of ocean and atmosphere general circulation model (GCM) output based on xarray and dask.” In a quote from the motivating documentation leading to the workshop:
It is our determination that xarray and out-of-core [dask] are the future of climate-related computation using Python, and conversely that Python is the future of climate-related computation. This puts us in a unique position to introduce a set of tools that becomes the community standard and greatly enhances the speed and reliability of such computations and therefore of the science itself.
At that workshop, the group coined the name Pangeo, and a few months later we began writing the NSF EarthCube award that would launch Pangeo as a project.
Over the next few years, the Pangeo project illuminated a number of insights. A good data model (e.g., Xarray) and API can empower scientists to focus more on science, rather than scripting and coding. Interoperability across packages can enable broad open development and integration, and packages with a narrow focus and clear APIs can expose potential for interoperability. Cloud computing can support scientific analysis in ways that HPC cannot, and that cloud computing exposes new ways for extensive collaboration. Lastly, providing scientists with access to “analysis ready” data is critical.
At NCAR, this project led to the launching of NCAR’s own JupyterHub as well as numerous multi-day tutorials and hackathons.
The Community¶
Today, Pangeo is a community that spans the entire globe “promoting open, reproducible, and scalable science” (see https://pangeo.io). At the writing of this document (1/12/2022), there are 373 contributing members in the Pangeo GitHub organization, 854 members of the Pangeo Discourse community, and 4296 followers of the @pangeo_data Twitter feed.
While the numbers suggest some measure of success, the real value provided by the Pangeo community is as a community of practice, where like-minded individuals can go to learn from each other and collaborate on the development of new software and new techniques. Pangeo’s Mission Statement clearly states this:
Our mission is to cultivate an ecosystem in which the next generation of open-source analysis tools for ocean, atmosphere and climate science can be developed, distributed, and sustained. These tools must be scalable in order to meet the current and future challenges of big data, and these solutions should leverage the existing expertise outside of the geoscience community.
The Stack: Pangeo Environments¶
The Pangeo community doesn’t advocate for a single monolithic software application or stack. In fact, the Pangeo community primarily advocates for technologies that are interoperable, extensible, and portable.
Rather than designing and creating a single monolithic application, our vision is an ecosystem of tools that can be used together. We want you to be able to easily build your own Pangeo, whatever that means to you.
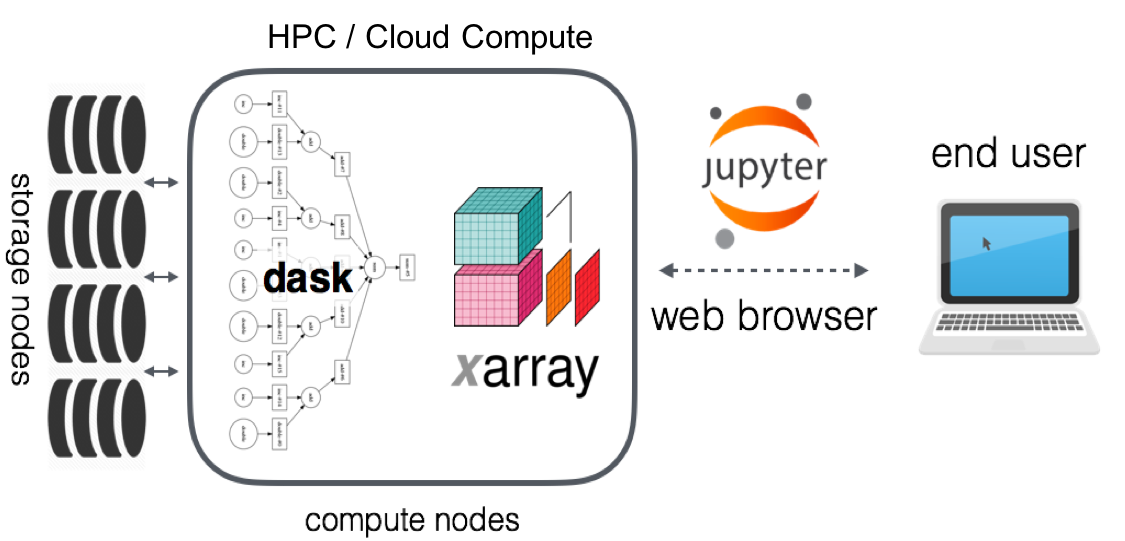
Fig. 1 The original technical architecture for Pangeo.¶
While the original Pangeo architectural model consisted only of Xarray, Dask, and Jupyter (as depicted in the figure above), Pangeo has evolved to allow for a wide variety of compatible packages and technologies, as long as these technologies are interoperable. Pangeo does strongly encourage the use of Xarray and Dask, but it is not required to be “Pangeo.”
A note on interoperability
One of the primary mechanisms used in the scientific Python community for developing technologies that are interoperable is by conforming to a “standardized” API. For Pangeo, this means conforming to the API defined by the most popular core data representations of the scientific Python ecosystem: Pandas and NumPy. Xarray builds upon both of these by providing a Pandas-like API for NumPy-like data arrays. Hence, any NumPy-like array (or drop-in NumPy replacement) can be “handled natively” by Xarray. The same is true for Dask, which provides distributed data representations for both DataFrames (i.e., Pandas-like) and DataArrays (i.e., NumPy-like), which are (mostly) drop-in replacements for Pandas DataFrames and NumPy ndarrays. This means that Xarray data can be represented by Dask DataArrays (which themselves are composed of many NumPy ndarrays or CuPy ndarrays), Legate NumPy arrays, or any other “NumPy-like” array. This is one of the primary reasons why Xarray is so strongly encouraged by the Pangeo community; Xarray provides a common layer of abstraction for climate and weather data.
In practice, the Pangeo community defines a Pangeo Environment as a system in which the user can select to use different “interchangeable components” with which to do their analysis: a Data Model, an Array Structure, a Processing Mode, and a Compute Platform. (See the following diagram.) A user selects each of these interchangeable components based on different criteria.

Fig. 2 Interchangeable components composing a Pangeo Environment¶
Data Model¶
There are currently two different supported Data Models: Xarray and Iris. Iris is primarily used at the UK MetOffice, as it is primarily tailored for their weather forecast data and its specifically designed metadata. Xarray is arguably more general, and can convert to and from Iris objects, if one so chooses. Hence, the determining factor in selecting the Data Model is the kind of data (and metadata) one uses.
Array Structure¶
The Array Structure can currently be NumPy ndarrays or Dask DataArrays (which, by default, are composed of NumPy ndarrays). The difference is whether the data is distributed or not, but since Xarray can deal with any kind of NumPy-like array (see the note on interoperability above), it would take little effort to build an Xarray object from any other kind of NumPy “drop-in” replacement, such as Legate NumPy arrays. Hence, the determining factor in selecting the Array Structure is how you want the data represented on your hardware.
Compute Platform¶
The Compute Platform can be either an HPC or a cloud platform. Deployment of the Pangeo Environment on each Compute Platform (sometimes called a Pangeo Platform) must be handled by an administrator, and the purpose of the Pangeo Environment concept is to make each deployment look and feel (essentially) the same. There are obvious differences in what one can do on different platforms, how each deployment will perform, and what additional software can be used or is available. For example, cloud platforms can scale elastically, while HPC platforms can be less flexible with immediate demands. Also, cloud platforms are great for open access to data, while HPC platforms tend to have limited access. However, the overarching goal of Pangeo is to make every Pangeo Environment feel the same by abstracting away the specific kind of deployment. Why have so many different deployments? Because the user should choose to do their analysis where the data they want to use resides. Hence, the determining factor in selecting the Compute Platform is where your data resides.
Processing Mode¶
Lastly, the Processing Mode is usually either batch or interactive. Batch processing is still useful for canned operations or stable operations that, even when parallelized, take an excessively long time. Interactive processing, on the other hand, is ideal for scientific exploration of data, “curiosity-driven” analysis, and unstable (i.e., still in development) operations. There are examples of “serverless” Processing Modes using AWS Lambda, too. Hence, the determining factor in selecting the Processing Mode is the kind of analysis.
Initiatives¶
Currently, the Pangeo community is focused on four unique initiatives: Cloud Operations, Machine Learning, Project Pythia, and Pangeo Forge. Each of these initiatives is represented within the Pangeo community by a Working Group, which usually holds regular meetings in a public forum to which anyone in the Pangeo community can attend.
Cloud Operations¶
The Cloud Operations working group was created to discuss and share experiences with deploying Pangeo Environments in the cloud, notably on the Google Cloud Platform (GCP), Amazon Web Services (AWS), and Microsoft Azure Cloud. This working group continues to meet and discuss to tackle specific questions of how to update specific deployments of Pangeo Environments. Much of this knowledge is codified in documents maintained by the working group and made public via the Pangeo website.
Machine Learning¶
The Machine Learning working group discusses machine learning challenges within Pangeo Environments. Much of the discussion, as far as I am aware, has been around restructuring data from Xarray formats to feed into ML frameworks like Keras and Tensorflow. For example, the Xbatcher package was created to aid with this:
Xbatcher is a small library for iterating xarray DataArrays in batches. The goal is to make it easy to feed xarray datasets to machine learning libraries such as Keras.
There is also a much larger NASA-funded project that has come out of work from this working group to aid with interoperability between the Pangeo stack and ML frameworks called Pangeo ML.
Education: Project Pythia¶
The Education working group was formed in the early Pangeo days, but its progress was slow and limited. One result from this working group is the Pangeo Gallery, a gallery of Binderized Jupyter Notebooks (and Notebook collections) that demonstrate the use of Pangeo in a wide variety of use cases. The Gallery has grown substantially since its creation, and it is a well-used and appreciated resource by the user community.
With the funding of Project Pythia, the Education working group was superseded by Project Pythia. Now, Project Pythia is leading the formation of an online resource for geoscientists to learn and navigate the scientific Python stack, and the Pangeo stack, as well.
Pangeo Forge¶
Pangeo Forge is Pangeo’s project to use continuous integration (CI) services to automate the production of Analysis Ready, Cloud Optimized (ARCO) data for public access in the cloud. The idea behind Pangeo Forge is to borrow the concept that has made Conda Forge so successful, namely to use CI to automate the production of installable Conda packages. With a recipe, users will be able to use Pangeo Forge to transfer and reformat (e.g., into Zarr format) public datasets for use on the cloud. There is enormous potential from this project for NCAR’s own efforts (see the Science @ Scale initiative) to move its data to the public cloud, as well as hosting analysis-ready datasets on NCAR’s own platforms.
Pangeo & NCAR Partnerships¶
NCAR has partnered with the Pangeo community on a number of initiatives, including a number of funded projects, starting with the original Pangeo NSF Earthcube award. This award lead directly to the deployment of NCAR’s JupyterHub, and it motivated our first Python/Pangeo tutorials and hackathons at NCAR in 2018 and 2019. The Pangeo collaboration’s connections with Project Jupyter led to the launching of the NSF EarthCube-funded Jupyter Meets the Earth project, and the Pangeo project’s success led to Project Pythia. In addition to traditional federally-funded projects and grants, Joe Hamman has also demonstrated that it is possible to fund NCAR work via non-traditional approaches, including an award from the Chan-Zuckerberg Initiative (CZI). NCAR is considered an Institutional Partner with Pangeo, being a collaborative recipient of many Pangeo-related awards.
NCAR has also made an internal commitment to Pangeo through the creation of the Experimental Development Team (Xdev) and the Earth System Data Science (ESDS) initiative. Both ESDS and Xdev are committed to the Pangeo community and the Pangeo mission, and, in fact, the creation of both ESDS and Xdev was motivated by Pangeo.